 A Theory of Stuttering
A Theory of Stuttering
A Theory of Stuttering
In the following Figure 4, the Figures 2 and 3 have been combined into a simple model of speech production. It further combines (1) Levelt’s model with its two feedback loops, but without separation between formulation and articulation (see the footnote in Section 1.1), and (2) Engelkamp and Rummer’s (1999) model of word forms and speaking programs (see Section 1.2). Note that not all functions depicted in Figure 4 are active at the same time; this is the case with the external and internal auditory feedback as well as with self-formulated speech and repetition. Concepts are not a third kind of word representations in addition to acoustic word forms and speaking programs. Instead, a concept (the content and meaning of a word) consists of links to other words (primarily their acoustic word forms) and to non-linguistic representations (see the footnote in Section 1.2).
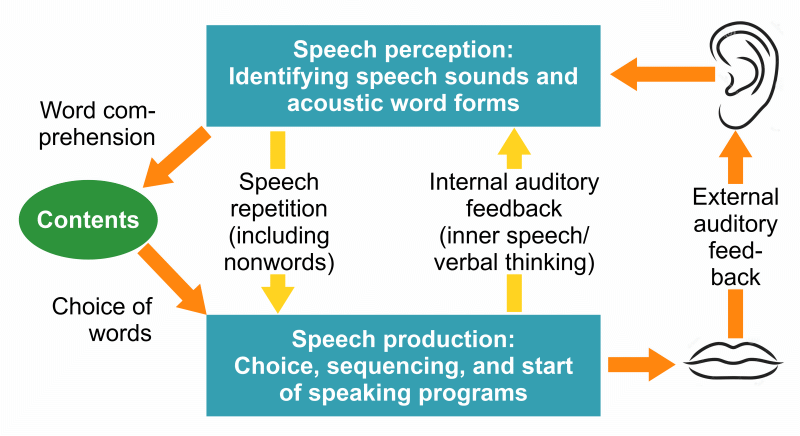
Figure 4: Model of speech processing. Note that not all functions are active at the same time. Orange arrows: functions during normal, spontaneous speech.
In the figure, an arrow labeled ‘internal auditory feedback’ connects speech production with speech comprehension. This connection in the brain enables us to produce and to perceive and understand speech internally in silent reading and verbal thinking. Moreover, internal auditory feedback also allows us to speak overly without difficulty when external auditory feedback is not available because of loud noise or hearing loss. The existence of internal auditory feedback and the absence of stuttering during silent reading and verbal thinking have largely been ignored in stuttering research. But both have to do with one another, and understanding why will help us understand the nature of stuttering.
Inner speech, the “little voice inside our head” that we hear in thinking or silent reading, has been investigated intensively in the context of reading and writing ability, working memory, and schizophrenia (see Alderson-Day & Fernyhough, 2015; Perrone-Bertolotti et al., 2014, for an overview). Two aspects or components of inner speech have been distinguished: a production aspect, sometimes referred to as ‘internal articulation’ or ‘subvocalization’, and a perception aspect, sometimes referred to as ‘inner hearing’ or ‘auditory verbal imagery’ (e.g., Hurlburt, Heavey, & Kelsey, 2013; Oppenheim & Dell, 2010; Tian, Zarate, & Poeppel, 2016). Smith, Wilson, and Reisberg (1992, 1995) simply distinguish between ‘inner voice’ and ‘inner ear’. Tian and Poeppel (2010, 2012) describe the connection between the production and perception of inner speech as a motor-to-sensory transformation.
Inner speech is not objectively observable; it has been investigated indirectly, e.g., by having subjects speak overtly with complete auditory masking (Brocklehurst & Corley, 2011; Oppenheim & Dell, 2008; Postma & Kolk, 1993). Oppenheim and Dell (2010, p. 1147) distinguish between “inner speech without articulatory movements” and “articulated (mouthed) inner speech”; according to this, mouthing (also referred to as lipped speech or pantomime speech) can be considered inner speech plus silent articulation. These relationships between overt and inner speech are important for a proper understanding of the phenomenon of inner speech: there is a transition from overt speech to whispering to mouthing to inner speech.
Inner speech has nearly the same articulatory richness as overt speech, including syllabic structure, linguistic stress, and prosody (e.g., Ashby & Clifton, 2005; Alderson-Day & Fernyhough, 2015). You can speak internally at a low or high rate (Alexander & Nygaard, 2008; Shergill et al., 2002), in an altered voice (McCarthy-Jones & Fernyhough, 2011; McGuire et al., 1995, 1996), and with voluntary (pseudo-) stuttering (Ingham et al., 2000).
Further evidence for the similarity of inner and overt speech comes from studies of error detection by the speaker during overt versus inner speech. Postma and Noordamus (1996) conclude from their results that inner speech depends on the same phonetic plan as overt speech does. Likewise, Oppenheim and Dell (2010) conclude that “planning processes may be highly comparable in conditions that require actual speech motor execution [...] compared to those which do not” (p. 390). Brocklehurst and Corley (2009) found that the phonemic similarity effect (the tendency of phoneme substitution errors to occur most readily with similar phonemes) had the same magnitude in overt and inner speech. They conclude that “plans for inner speech were fully specified at the featural level, even in the absence of any intention on the part of the speaker to utter the words overtly.” In a similar study, Corley, Brocklehurst, and Moat (2011) conclude that “our ‘inner voice’ sounds much like our overt speech, and is produced in much the same way, whether overtly articulated or not” (p. 172).
Motor control is involved in both overt and inner speech. According to Tian and Poeppel (2010, 2012), inner speech depends on motor simulation; it is controlled by sequences of motor commands (in my terminology, speech-motor programs) just as is overt speech. Neuroimaging studies have shown that inner speech is associated, among others, with activations in motor and premotor areas (Brumberg et al., 2016; Kell et al., 2017; McGuire et al., 1996; Palmer et al., 2001; Shergill et al., 2002; Tian & Poeppel, 2012; Tian, Zarate, & Poeppel, 2016). EEG studies revealed that inner speech is accompanied by almost unnoticeable movements of lips, tongue, and laryngeal muscles (see, e.g., Edfeldt, 1960; Locke, 1970, for an overview). Even respiration shifts from the basic mode into the speech mode during inner speech, despite the lack of phonation (Conrad & Schönle, 1979).
Fernyhough (2004) has sketched out a model of how inner speech develops in childhood: a gradual transition takes place from loud self-talk via whispering and mouthing to inner speech/verbal thinking (see also Alderson-Day & Fernyhough, 2015). First, children learn to form sentences overtly until, roughly around the age of five, their overt speech reaches a functional stage that allows internalization (Conrad, 1971). Four-year-olds usually have no knowledge and no awareness of inner speech (Flavell et al., 1997).
That means that inner speech (silent verbal thinking) is not the basis of overt speech. Conversely, overt speech forms the basis of inner speech and verbal thinking. During verbal thinking and silent reading, speech-motor programs run in nearly the same way in the brain as during overt speech with the only difference that the execution of most of the muscle movements is suppressed (read more). Given the similarity between inner and overt speech, particularly regarding the involvement of motor control, the absence of disfluency during silent reading and verbal thinking in most stutterers is not trivial, and an explanation of this phenomenon will help us understand the nature of stuttering.
The suppression of overt articulation during inner speech requires additional muscular effort: the mouth is tightly closed, the lips are compressed, the tongue presses against the palate, and the breath is often held. Since the suppression of overt articulation requires additional effort, thinking about a complex issue or solving a difficult mental arithmetic problem is easier if you can at least whisper (“think aloud”).
(return)