 A Theory of Stuttering
A Theory of Stuttering
A Theory of Stuttering
A longer utterance is composed of phonemes, syllables, words, phrases, clauses, and sentences, but it also contains pauses to breathe in. I refer to all these differently long and differently complex units as ‘speech units’ or simply as ‘units’. Most of these units in themselves are sequences of lower complex units. Some kinds of units, such as clauses and sentences, are variable, that is, novel units of this kind are produced every day. Other kinds of units, such as phonemes, syllables, words, and idioms, are relatively invariable. Sometimes, novel words and idioms are created, but novel syllables or phonemes hardly emerge in one’s native language. Based upon the considerations in the last section, we can assume that the articulation of relatively invariable speech units, after they have been automated, is feedforward-controlled by motor programs.
The existence of speech-motor programs is, for instance, assumed in the DIVA model (see, e.g., Guenther, 2006). Segawa, Tourville, Beal, & Guenther (2015) define speech-motor programs as “stored neural representations that encode the sequence of movements required to produce the utterance”. There may be learned motor programs for the production of all phonemes, syllables, familiar words, and frequently used phrases and idioms. Speech-motor programs are structured hierarchically: the program controlling the production of a syllable is the sequence of the programs for the phonemes, etc.
A further argument for the thesis that motor programs control the production of relatively invariable speech units comes from Engelkamp and Rummer (1999). Based upon the results of aphasia research, they proposed a psycholinguistic model in which a word is represented in the brain in two different ways: as an acoustic word form and as a ‘speaking program’, a motor program controlling the production of the word. Figure 2 shows the relationship of acoustic word forms and speaking programs to concepts.
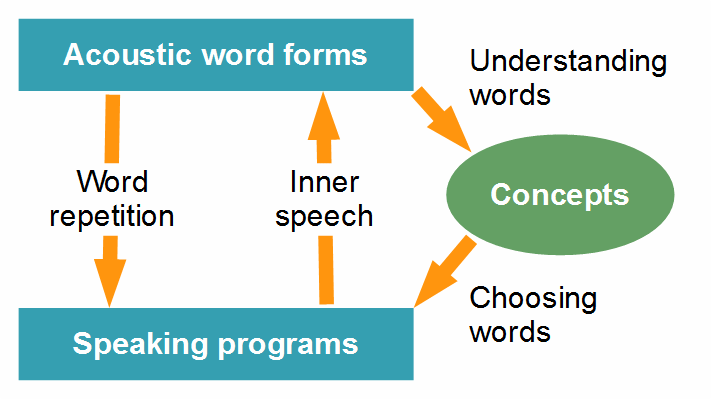
Figure 2: Acoustic word forms (= auditory memories/imageries of what words sound like) and speaking programs (= motor routines for the production of words). Only relationships within the brain are depicted (compare Fig. 4).
An acoustic word form allows us to recognize (identify) a perceived word and to understand it, that is, to associate it with the respective concept. The speaking program, by contrast, controls the production of the word. It enables us to immediately express the concept, as we usually do in spontaneous speech, without remembering the acoustic word form before. The acoustic form and the speaking program of a word are linked not only via the concept (the semantic content) but also directly. We are quite able to repeat a phoneme sequence we have just heard, even if the content is unknown to us or if no content exists (nonword repetition). The ability to immediately repeat a sound sequence enables us to learn new words by imitation and is the basis of language acquisition. The reverse direct link, from speaking programs to acoustic word forms, is essential for verbal thinking (inner speech; see below).
A speaking program is a motor routine acquired by the repetitive production of a speech unit, that is, by practice. The speaking program of a multisyllabic word contains both, the phoneme sequence and the syllable structure, including linguistic stress (word accent). Therefore, phoneme sequence and syllable structure do not need to be synchronized by the brain; this synchronization is already contained in the speaking program. When you learn to speak a new word, you acquire and automate the phoneme sequence, the syllable structure, and the linguistic stress together and concurrently.
From the fact that the speaking program of a word contains the phoneme sequence, it further follows that the brain does not need to put a familiar word together out of the phonemes before speaking (phonological encoding). The consequence for a theory of stuttering is that, for the production of all familiar speech units being controlled by speaking programs, we can exclude difficulties in phonological encoding or in synchronizing phoneme sequence with syllable rhythm as the cause of stuttering.
Engelkamp and Rummer (1999) only claimed that the production of words is controlled by speaking programs. But it might be true for all speech units we can ‘reel off’ immediately from memory without any decision on articulation or formulation (read more). Therefore, not only words but also frequently used phrases, idioms, and proverbs might be controlled by speaking programs but even memorized poems and lines of an actor’s part. Besides, there are, of course, speaking programs for all familiar syllables and phonemes, such that we can compose them into new words or speak them individually, e.g., in spelling. In everyday talking, however, a speaking program usually controls the production of a word or a short phrase.
The above can be summarized as follows: The spontaneous production of familiar words and phrases is not so much a matter of planning but rather of behavioral routines: “words are learned motor sequences.” (Van Riper, 1971, p. 393). Those motor sequences, after they were acquired and automated by repetition, are feedforward-controlled by motor programs (‘speaking programs’). An alongside-running, automatic, and widely unconscious monitoring ensures that the next speaking program can only be executed if the previous one is correct and complete. The latter is the topic of the next page.
Davis and Redford (2023) have proposed a dual lexicon model similar to that suggested by Engelkamp and Rummer (1999). Their model was not inspired by aphasia research but developed as a framework for understanding the limitations of perceptually-driven changes to production, e.g., during speech acquisition. Davis and Redford assume that “a lexicon of motor and perceptual wordforms linked to concepts and whole-word production based on these forms. Motor wordforms are built up with speech practice.” (p. 1) Their model thus “presents a word-based alternative to the phoneme-driven model of production.” (p. 2)
Patients affected by Broca’s aphasia understand spoken language but have difficulty finding the words when speaking. They speak disfluently, search for words, and frequently use paraphrases. In contrast, patients suffering from Wernicke’s aphasia speak fluently but have difficulty with speech comprehension, including monitoring their own speech. Often, they cannot formulate coherent, intelligible sentences. These observations suggest that the production of familiar words and phrases is independent of speech comprehension and based on motor routines.
(return)
Engelkamp and Rummer (1999) call them ‘acoustic word nodes’, referring to a connectionist model of speech processing. I prefer the more neutral term ‘acoustic word form’ because the difference between connectionist and hierarchic models of speech processing, in my view, plays no role in answering the question about the cause of stuttering.
(return)
The basis of language comprehension is that words are associated with nonverbal representations, that is, with visual, acoustic, or other sensory impressions and experiences that have been kept in memory. The word ‘dog’, for instance, is linked to a visual pattern that allows us to identify an animal we see as a dog. Additionally, there are links to acoustic memories of barking and to other memories of personal experiences with dogs. They are nonverbal representations that give the word ‘dog’ (the acoustic word form as well as the speaking program) content and meaning.
However, what kind of nonverbal representation are words like ‘and’ or ‘definition’ associated with? When trying to explain the meaning of such words, we can’t refer to sensory impressions. Instead, we must paraphrase the word by means of other words. The contents of most of the words in an adult’s vocabulary mainly consist of links to other words. That means that concepts are not a third kind of word representation in the brain, in addition to acoustic word forms and speaking programs, but networks of links between representattions.
The following consideration makes it clear that acoustic word forms and speaking programs exist independently of semantic contents. With some practice, you can learn to speak and memorize a nonword like /matula/ so that you can recognize it if you hear it some days later and that you can always speak it like any other word. In this way, you have acquired both, the acoustic word form and the speaking program of /matula/, although it has no content.
(return)
The idea that the brain transforms concepts into words and puts the words together out of the phonemes to generate a ‘phonetic plan’, from which then a sequence of articulatory movements is derived—this idea is very common and part of the model of speech production proposed by Levelt (1995). But when speaking a familiar word, I don’t need to remember its phoneme sequence to articulate it. Instead, I immediately access the speaking program, that is, the program controlling the motor sequence. I start the speaking program of the word, and I hear its acoustic form (the sound sequence) while I’m speaking it. To remember the sound sequence before speaking is only necessary if I’m not sure about how to articulate the word correctly, that is, with unfamiliar words.
Note that the articulatory routine controlling the production of a familiar word contains not only a sequence of phonemes, as they are symbolized by the letters of the alphabet, but also the transitions between them and all word- and dialect-dependent variations of the phonemes. We can even spontaneously vary these routines; for instance, substitute sounds in play for fun (e.g., kangaroo, kingaroo, kongaroo, kanguree, etc.), and many people can switch to a foreign or regional accent. Such articulatory freedom can hardly result from a computational process like the phonological encoding of entries in a mental lexicon, as assumed in Levelt’s model. It is much better explained as the variation of a motor routine.
In my view, the idea of a ‘phonetic plan’ and ‘phonological encoding’ is fundamentally wrong because the brain is not a computer. Speaking is not controlled by computation but by learned motor routines. Only when we learn to speak a new word, the motor sequence must first be put together of speaking programs of phonemes or familiar syllables, before it can be automated by repetition and practice.
(return)
We should consider that our linguistic categories— phoneme, syllable, word, clause, sentence—are not relevant to sensorimotor control in the brain. For example, the basic sensorimotor programs for speaking might rather be frequently occurring sound combinations learned in the babbling period than the pure single sounds of the alphabet; therefore, there might be no difference between phonemes and syllables on the level of speaking programs. Moreover, syllables are often used as monosyllabic words, without any difference being on the level of articulation, that is, in terms of speaking programs.
Likewise, the difference between words, phrases, clauses, and sentences might hardly play a role in motor control. Frequently used phrases and short sentences such as “How do you do?” might be produced like words by only one speaking program; but to learn a new and long word, for example, a German compound like Bundesverfassungsgerichtsurteil (federal constitutional court act) might require sequencing, similar to what is normally required in sentence production.
By the way, since acoustic word forms and speaking programs are principally independent of semantic content (see 3rd footnote), we have not to assume the existence of a ‘mental syllabary’, a particular register of syllables without semantic content. There is no essential difference in the brain between speaking programs for familiar words and phrases or a memorized poem, on the one hand, and for syllables and phonemes, on the other hand. Speaking programs may be extremely different in complexity and degree of hierarchy, but their key common feature is that they are sensorimotor routines acquired through learning and repetition. This will be relevant for the theory of stuttering proposed in Chapter 2.
(return)