 A Theory of Stuttering
A Theory of Stuttering
A Theory of Stuttering
Connected speech can be considered a particular, complex sequential behavior; that is, a behavior composed of several consecutive steps or segments. Such steps are the production of a phoneme, a syllable, a word, or a clause. There is a hierarchy of differently complex sequences in speaking: a syllable is a sequence of phonemes, a word is a sequence of syllables, a phrase is a sequence of words, and so on. We can also say that speech is a sensorimotor sequence: a sequence of motor actions as well as sensory perceptions, with both being closely linked to one another.
In some kinds of sensorimotor sequences, for example, making a bow, a certain number of movements must be done in a certain order to accomplish a goal. But not so in speaking. Indeed, the motor sequence for the production of a certain word, e.g., the word “book,” is nearly always the same, similarly as in making a bow, but the sequences of words in sentences are not. Their order is determined by syntactic rules, but those rules allow a nearly unlimited variety of wording, depending on the intended meaning. The result of the movement sequence for making a bow, if successfully completed, is always a bow; the result of a speech sequence may be a sentence never said before.
A question important for a theory of stuttering is how sensorimotor sequences are controlled by the brain in a way that they can be executed fluently. In the first half of the 20th century, experts believed that behavioral sequences were feedback-controlled; that is, the perception that the current step has been completed triggers the start of the next step. The main argument against this view is that some time is needed from feedback perception to reaction, namely about 150 ms or more. Because of that reaction time, a purely feedback-controlled sequence could never be fluently executed. A further argument against purely feedback-based control is that sensorimotor sequences, once they have been automated, can be executed even if sensory feedback is interrupted. This is also true for speaking.
It was who showed that sequential behavior cannot be controlled by sensory feedback alone. He proposed a hierarchical organization of ‘plans’ – today, we would rather say programs – that allow a feedforward control of sensorimotor sequences. Meanwhile, Lashley’s position is regarded as confirmed (see, e.g., Rosenbaum et al., 2007). However, Lee (1951) and Stromsta (1959) demonstrated that a healthy person’s speech flow can be severely disrupted by manipulation of auditory feedback. Furthermore, Kalveram and Jäncke (1989) showed that even a delayed auditory feedback (DAF) of 40 ms, which is below the threshold of conscious perception, affects the timing of speech. These facts indicate that speaking is not purely feedforward-controlled; obviously, auditory feedback plays some role (read more).
By the way, not only auditory feedback but also proprioceptive, tactile, or kinesthetic feedback, that is, feeling the movements of vocal folds, jaws, tongue, and lips, the contact of palate, tongue, and lips, etc., influence speech contro. Imagine, for instance, how the anesthesia of tongue, lips, and palate would alter the quality of articulation. I will not further deal with these kinds of sensory feedback here, since I don’t believe that they are involved in the causation of stuttering. An exception perhaps is the sensory feedback of breathing; see Section 2.2.
Let us now consider how a sensorimotor sequence is acquired. At least in the initial phase of learning, it is necessary to evaluate whether the current step has been successfully completed so that the next step can start. If an error occurs, it is best to stop the sequence and repeat the step in question; otherwise, the entire sequence would fail. Therefore, continuous self-monitoring develops and ensures that each step is correctly executed and errors are repaired immediately. The steps of a sequence and their succession are indeed feedforward (program-) controlled, but self-monitoring is an element of feedback-based control.
In learning a sensorimotor sequence, the self-monitoring is conscious, and the execution is not yet fluent because short breaks are needed to evaluate each step. Later, after the sequence has become automatic, self-monitoring runs unconsciously alongside. In tying a bow, you don’t consciously monitor whether every partial movement has been completed before starting the next one. However, if something has gone wrong, you notice it immediately, stop the movement, and do it again properly.
Both kinds of control are depicted in Figure 1. Above, a sequence in the initial period of learning is shown. The single steps themselves are program-controlled, but the control of the sequence is rather feedback-based; the success of every step is consciously perceived (arrow to the monitor), and the next step starts as a response to the feedback that the preceding step is complete (arrow from the monitor). If an error has been detected, the affected step is repeated.
Below in Figure 1, a sequence already automated is shown. The success of every step is monitored as well, but now monitoring is automatic and unconscious. The next step doesn’t start as a reaction to feedback, but by a program controlling the entire sequence (the horizontal arrow; it also symbolizes the timeline). If an error is detected, the monitor stops the movement after a reaction time, and the affected step is repeated correctly before the sequence is further executed.
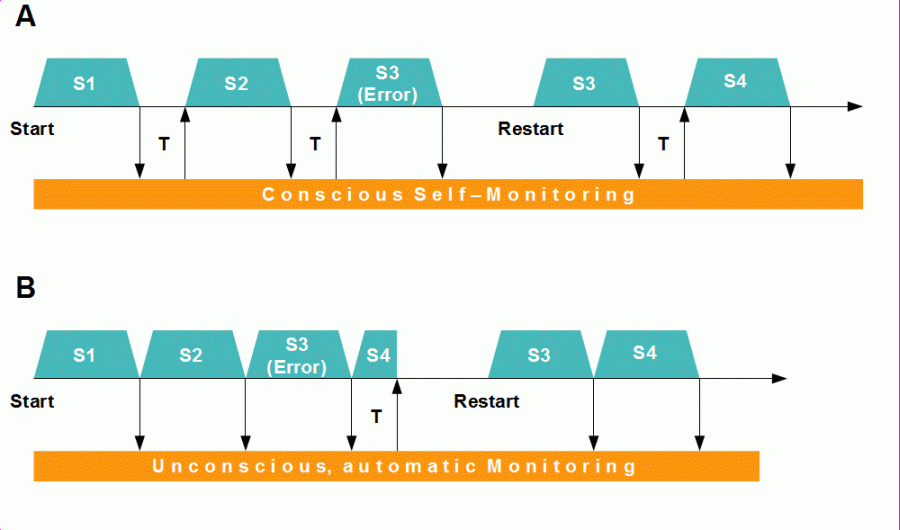
Figure 1: Feedback-controlled (A) and feedforward-controlled (B) sensorimotor sequence. S = step (segment, submovement), T = reaction time.
In summary, we can say that, in an automated sensorimotor sequence, self-monitoring is an alongside-running, feedback-based element of control. It ensures that the next step can only start if the preceding step is correct and complete. The automatic unconscious monitor intervenes only if an error is detected and after a reaction time. It is, however, important to understand that this monitoring-and-interruption mechanism is more than merely a mechanism for error correction. It is an essential part of control because it enables us to learn and automate the correct and fluent execution of sensorimotor sequences.
Looking at the brain, we find the cerebellum to be the structure crucial for the sequencing of motor programs. Hallett and Grafman (1997) assumed the cerebellum to be involved in the organization of sequences of both, movement patterns and mental operations. Molinari, Leggio, and Silveri (1997) suggested that the cerebellum operates as a “controller” mediating sequential organization of the various subcomponents of complex cognitive tasks. Based on morphological and electrophysiological data, Braitenberg, Heck, and Sutlan (1997) proposed that the cerebellar cortex acts as a “sequence-in/ sequence-out operator” transforming input sequences of events into a coordinated output sequence. Ackermann, Mathiak, and Ivry (2004) applied this model to the domain of speech production and proposed that a left-fronto/right-cerebellar network subserves the ongoing sequencing of speech movements. Whereas the right cerebellar hemisphere seems to be responsible for sequencing, the left cerebellar hemisphere is involved in self-monitoring and error repair in motor sequences, and it seems to play a crucial role in the causation of stuttering (see here in Section 2.1).
From a psycholinguistic viewpoint, Levelt’s Perceptual Loop Theory and his Main Interruption Rule describe the alongside-running, feedback-based monitoring in the control of speech. An automatic and unconscious monitor continuously checks the elements of the speech sequence, that is, the words, phrases, and clauses just spoken, and interrupts the speech flow immediately if an element appears erroneous (read more about Levelt’s model of speech production).
Lee (1951) showed that a delay in the auditory feedback of speech of about one syllable length (1/4–1/5 second) leads to speech disfluencies in normally fluent speakers. Repetitions and prolongations occur, as do speech tempo fluctuations and formulation errors like incorrect or suddenly canceled sentences (see also Fairbanks & Guttman, 1958). These behaviors are referred to as the ‘Lee effect’ today. Lee himself called them “artificial stutter”; however, they are significantly different from those typical of true stuttering: they are not accompanied by muscular tension, and repetitions mostly occur at the end of words. Stromsta (1959) caused short blockages of phonation in normally fluent speakers by phase shifting of the auditory feedback, which provided additional evidence for auditory feedback to influence speech flow.
By means of time-altered auditory feedback (delayed,as well as premature) of 20–60 ms, which is below the threshold of perception, Kalveram (1983) discovered that the duration of long, stressed syllables is controlled based on auditory feedback. He referred to the phenomenon as ‘audio-phonatory coupling’ (see also Kalveram & Jäncke, 1989>). The effect indicates a feedback-based online control of vowel duration in long-stressed syllables, that is, in syllables that are stressed by speaking them not only louder but also a little longer; vowel offset depends on the auditory feedback of vowel onset. By contrast, the duration of short syllables was found to be not or very less influenced by altered auditory feedback. .
(return)
It might be the most influential model of speech processing today, and on the following pages, I will often refer to it; therefore, it is briefly presented here. The figure shows a simplified version confined to speech production and the two feedback loops. The figure is equal to Fig. 12.3 on page 470 in Levelt (1995).
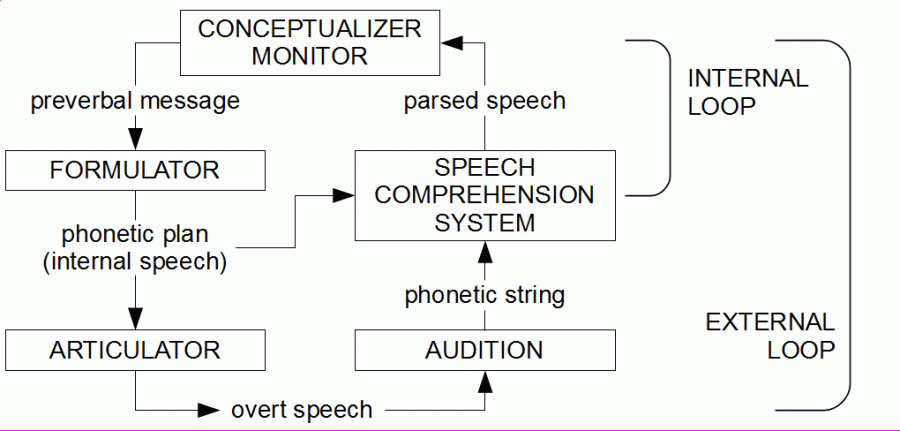
The main advantage of the model is that it describes the relationship between speech production and auditory feedback. On the following pages, however, I will argue against some positions of this model. Here, I only want to point to a general problem.
The investigation of speech errors (slips of the tongue) has played an important role in the development of psycholinguistic models of speech production (Levelt, 1999): A model of speech production can only be realistic if frequently occurring types of speech errors are possible in this model. However, what is true for speech errors should also be true for stuttering: a model of speech production can only be realistic if stuttering is possible within it. Let us consider Levelt’s model thoroughly in this respect.
Formulation and the control of articulation are localized in two separate ‘encapsulated modules’ in the brain, referred to as Formulator and Articulator. In the Formulator, a ‘phonetic plan’ is generated. This plan is sent to the Articulator, where it is converted into a sequence of commands for the executing muscles. Information is transferred only from the Formulator to the Articulator, but not the reverse. From that, the question arises: which of both modules is impaired in stuttering?
As a rule, stutterers are well able to formulate correct sentences; they have no difficulty thinking them or writing them down. Therefore, stuttering seems to be a disorder of articulation only – but the Articulator seems to be able to work well too: Stuttering, in a rule, does not occur when stutterers repeat single phonemes, single syllables, or single words, when they speak in chorus, or when they ‘Usually, stutterers are able to formulate correct sentences; they have no difficulty thinking them or writing them down. Therefore, stuttering seems to be a disorder of articulation only. But the Articulator is able to work well too: stuttering usually does not occur when stutterers repeat single phonemes, single syllables, or single words, when they speak in chorus, or when they ‘shadow’ the speech of someone else. Moreover, some stutterers fluently recite poems, and actors, who stutter in everyday situations, speak their parts fluently on stage. If both, Formulator and Articulator work well in themselves – is the information transfer from the Formulator to the Articulator impaired in stuttering? That can hardly be the case because stutterers always know exactly what they are going to say when they don’t get it out.
Obviously, neither Formulator nor Articulator nor the information transfer from the former to the latter seems to be responsible for stuttering, and an interaction between Formulator and Articulator is excluded in Levelt’s model and is thus out of the question as a cause of stuttering. Apparently, there is no place for stuttering in Levelt’s model of speech production. And there is a further problem: it is, at least, unclear what the person does and what the modules in the person’s brain do. If, in spontaneous speech, sentences were first formed by an unconscious internal Formulator (quasi behind the speaker’s back), then monitored (before articulation) by an unconscious internal censor, and finally spoken out, controlled by an Articulator – who, in the framework of this model, is responsible for what the speaker says?
Instead, I assume that, in spontaneous speech, sentences are formulated by being articulated, and they are monitored automatically via the external feedback loop, by hearing. That means: In spontaneous speech, a speaker does not know the exact formulation of a sentence before the sentence has been spoken. Therefore, it is not surprising that spontaneous speech is usually not perfect and contains errors and unfortunate wording. Occasionally, we say the wrong thing, notice it, and correct the mistake. Our responsibility in spontaneous speech is not to formulate perfectly, but to detect our mistakes and correct them immediately to avoid misunderstandings.
(return)